From Slack to Searchable Knowledge — How We Built Memonia’s Foundation
July 26, 2019 — Release
Table of Contents
- Why We Built Memonia
- From Conversations to Curated Data
- Building Labeled Datasets That Worked
- Normalizing, Labeling, and Learning
- What We Shipped
- What’s Next
1. Why We Built Memonia
By 2018, Slack had become mission control for modern teams. Ideas sparked in threads. Bugs were solved mid-sprint. Wisdom flowed — and vanished just as quickly.
Memonia began as an attempt to fix that.
Our goal: turn Slack conversations into reusable knowledge. We wanted Slack to remember which questions had already been answered, surface expert replies, and connect new questions to old solutions — automatically, semantically, and respectfully.
Memonia would live inside Slack, listening, learning, and eventually answering. But first, we had to teach it what “knowledge” even looked like.
2. From Conversations to Curated Data
The first problem we tackled was structural: how to capture and clean threaded Slack conversations. In those early days, we worked entirely with flat files and CLI tooling.
We built shell utilities to:
- Export full Slack histories
- Merge and flatten threads into message timelines
- Normalize Slack-specific quirks like mentions, emojis, and URLs
This gave us structured CSV files we could reason about, label, and version. Here's how the pipeline looked:

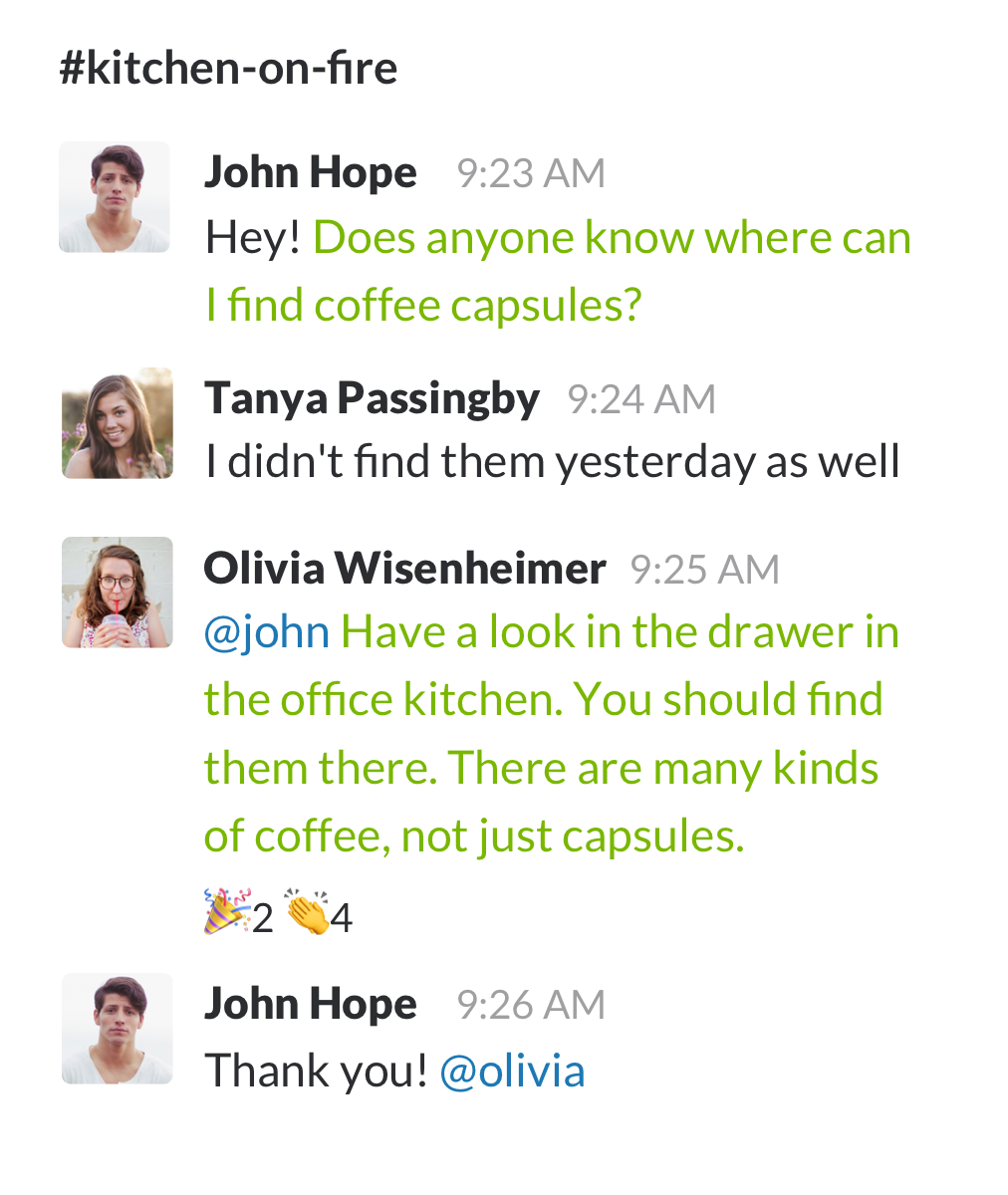
3. Building Labeled Datasets That Worked
To train models that understood questions and answers, we needed examples. Lots of them.
We began with genre detection: was a message a question, a solution, an article, or smalltalk? Then we tackled question type: was it general or context-based?
Our data sources included:
- Slack: real team conversations
- QuAC: dialogue-heavy Q&A
- StackExchange: long-form answers
- Twitter & Ubuntu chats: informal, noisy messages
- SQuAD: reading comprehension pairs
These weren’t plug-and-play. Each source required its own set of extraction and cleaning scripts, careful quoting fixes, and schema checks. We treated dataset curation as its own engineering effort.
This cross-source pipeline gave us variety, scale, and nuance:

4. Normalizing, Labeling, and Learning
We knew that naive text matching wouldn’t work. Slack messages were full of ambiguity:
- “What is SPSS?” — is that general knowledge, or a follow-up in a longer thread?
- “Thanks.” — acceptance or subtle rejection?
- “Which one?” — requires prior context.
So we iterated:
- Applied normalization (
rules.json) to make messages consistent - Developed regular expressions to spot question markers
- Labeled by hand when heuristics fell short
- Reviewed model failures to refine datasets
We also balanced datasets by label, de-duplicated repetitive questions, and preserved a “snapshot” mindset: every .csv was date-stamped, versioned, and linked to the exact extraction commands used.
The tooling was intentionally CLI-first — sed, grep, jq, csvkit, and shell scripts ruled the day.
5. What We Shipped
By mid 2019, Memonia could:
- Extract question–answer pairs from Slack threads
- Detect message genres and question types using ML
- Search across Slack, Confluence, and Google Drive
- Surface expert teammates who had answered similar things
- Let teams curate reusable knowledge snippets manually or automatically
Our stack was minimal but scalable:
- Slack bot written in Scala + Akka Streams
- NLP services exposed via Akka HTTP and Pub/Sub
- Datasets served as flat files, versioned and reproducible
- Elasticsearch for retrieval, RocksDB for quick lookups
Everything ran on Google Cloud. Our services could ingest messages, run predictions, store structured knowledge, and respond in-channel — all without leaving Slack.
6. What’s Next
This was just the beginning. In our next two posts, we’ll share:
← Read Post 2: Infrastructure Meets Intelligence
How we turned these datasets into a full system of microservices, APIs, and live inference pipelines.
← Read Post 3: Learning from the Data
How we trained and served models at scale using Spark, BigDL, and real production messages.