Can Agents Tune Diffusion LoRAs?
June 17, 2026 — Diffusion Models AutoResearch LoRA
This post's focus: what happened when an autonomous coding agent was asked to improve an SDXL style LoRA training recipe with only one editable file, a fixed evaluation harness, and a short training budget.
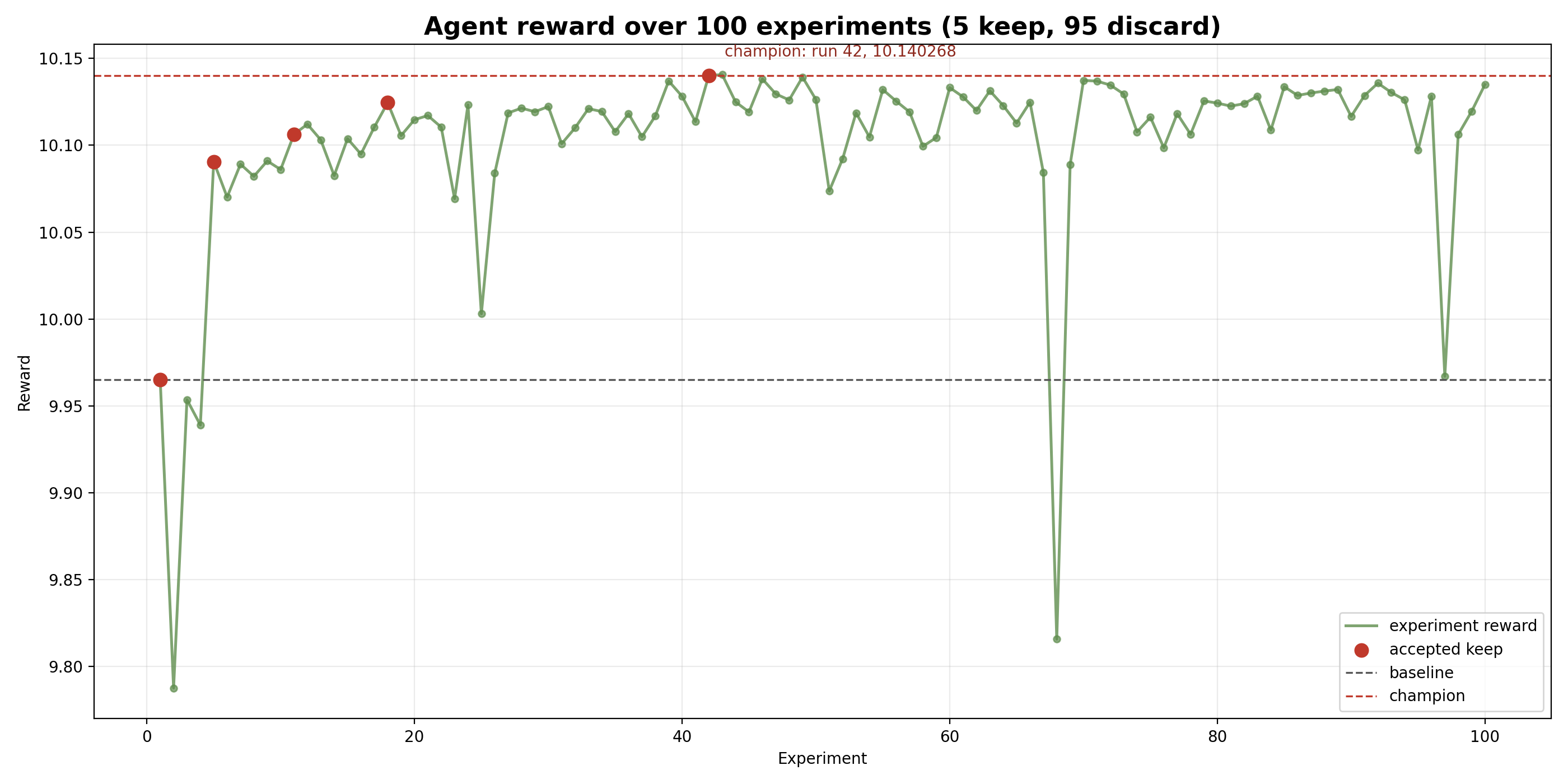
The short version: the agent did find an improvement. Across 100 experiments, it moved the short-run reward from 9.965098 to 10.140268, with 5 accepted recipe changes and 95 discarded trials. More importantly, the best recipe still beat the baseline after both were retrained for 2000 steps across three training seeds.
The caveat is just as important. The improvement transferred as a relative recipe advantage, not as a clean absolute reward prediction. The longer full-training rewards were lower than the short-run baseline, and the winning recipe traded off style similarity for stronger prompt/preference score and slightly higher diversity, while also increasing the memorization penalty.
That is the main result: autonomous diffusion recipe search can exploit real local structure, but the scalar reward is not stable enough to treat like language-model validation loss.
Table of contents
- The question
- The experiment design
- The reward signal
- What the agent found
- Full-training validation
- What changed qualitatively
- Interpretation
- Limitations
- Takeaways
1. The question
Karpathy's AutoResearch pattern is intentionally simple: give an agent a tiny research repo, let it edit one training file, run many short experiments, keep improvements, and discard failures. In the original setup, the target is a small language model, and the feedback signal is validation bits per byte.
That last detail matters. Language-model training gives the agent a clean scalar objective. Lower validation loss is not perfect, but it is meaningful enough to support hill climbing.
Diffusion personalization is messier. A LoRA for an image model can improve in one way and regress in another:
- it can match the prompt better while losing the target style,
- it can look more aesthetic while memorizing training images,
- it can improve one seed and fail another,
- it can optimize an automatic metric without actually producing better images.
So this project asked a narrower question:
Can an autonomous agent improve an SDXL style LoRA training recipe using only a fixed automatic evaluation harness?
The setup uses SDXL base 1.0, LoRA, and a Van Gogh subset of the HugGAN WikiArt dataset. The repo's current preparation code takes 100 Van Gogh images total, split into 90 training images and 10 validation images, all resized/cropped to 1024x1024.
2. The experiment design
The repo keeps the research surface deliberately small:
prepare.pybuilds the fixed dataset, prompts, seeds, and reference embeddings.train.pyis the only editable training script.arena.pyperforms candidate-vs-champion evaluation and promotion.program.mdtells the agent how to run the experiment loop.
The full reproducible repository is available at azolotenkov/diffusion-autoresearch.
The baseline trainer is intentionally plain: SDXL base, UNet-only LoRA, AdamW, cosine learning-rate schedule, one style caption, gradient checkpointing, and a fixed wall-clock training budget of 10 minutes. The baseline hyperparameters include rank 4, alpha 4, learning rate 1e-4, batch size 2, and 400 train steps.
The agent was allowed to mutate training-recipe choices in train.py, including LoRA rank/alpha, learning rate, scheduler details, batch size, training steps, caption dropout, weight decay, and target modules. It could not change the dataset, prompts, seeds, evaluation metrics, or promotion rules.
This matters because the experiment is not "can an agent make the number go up by changing the benchmark?" It is "can an agent find a better recipe under a fixed benchmark?"
3. The reward signal
The evaluation harness renders a fixed prompt suite with fixed seeds. The prompts include portraits, landscapes, still life, a city street at night, a cat on a chair, and an astronaut on the moon, all in the style token <vangogh>.
Each generated image is scored with a composite metric:
reward =
0.45 * preference_score
+ 0.35 * style_score
+ 0.20 * diversity_score
- 0.20 * memorization_penalty
The components are:
- Preference score: prompt-image alignment using PickScore, a CLIP-based scoring model trained from text-to-image preferences.
- Style score: maximum cosine similarity between generated image CLIP embeddings and reference Van Gogh image embeddings.
- Diversity score: average dissimilarity among generated image embeddings.
- Memorization penalty: a nearest-neighbor penalty based on DreamSim distance to training images.
The arena adds another gate. A candidate is promoted only if its reward improves by more than 0.01 and its pairwise win rate against the current champion is at least 0.55.
That rule prevented at least one misleading keep. Run 43 had a slightly higher scalar reward (10.140632) than the accepted champion (10.140268), but its win rate was only 0.5000, so it was discarded. The final champion was run 42, which had a slightly lower scalar reward but a stronger pairwise win rate of 0.6111.
4. What the agent found
Across 100 experiments:
| Metric | Value |
|---|---|
| Experiments | 100 |
| Accepted keeps | 5 |
| Discards | 95 |
| Baseline commit | 1260e61 |
| Baseline reward | 9.965098 |
| Short-run champion commit | 5e10fab |
| Short-run champion reward | 10.140268 |
| Short-run reward gain | +0.175170 |
| Champion win rate | 0.6111 |
The experiment history is archived as a Git bundle in the artifact set. In that bundle, the baseline commit is 1260e61, and the short-run champion commit is 5e10fab. The champion recipe changes the baseline LoRA rank/alpha from 4/4 to 6/6, lowers the learning rate from 1e-4 to 4e-5, and reduces training from 400 to 390 steps while keeping the same target modules, batch size, scheduler, warmup, and weight decay.
The important behavior is not that the agent found one magic setting. The trace shows local search: most later attempts stayed near the champion but failed the acceptance rule. The search space was narrow enough for the agent to try disciplined changes, and the arena was strict enough to reject many tiny scalar near-misses.
5. Full-training validation
Short-run wins can be misleading. A 10-minute LoRA run may reward undertraining artifacts or find a recipe that only looks good under the short budget. To check whether the result transferred, the baseline and champion recipes were both retrained for 2000 steps under the same fixed evaluation harness.
In the first full-training comparison, the champion still beat the baseline:
| Metric | Full champion | Full baseline | Difference |
|---|---|---|---|
| Reward | 9.947569 |
9.838474 |
+0.109095 |
| Style score | 0.739221 |
0.753927 |
-0.014706 |
| Preference score | 21.439605 |
21.159189 |
+0.280416 |
| Memorization penalty | 0.085989 |
0.016640 |
+0.069349 |
| Diversity score | 0.291087 |
0.281462 |
+0.009625 |
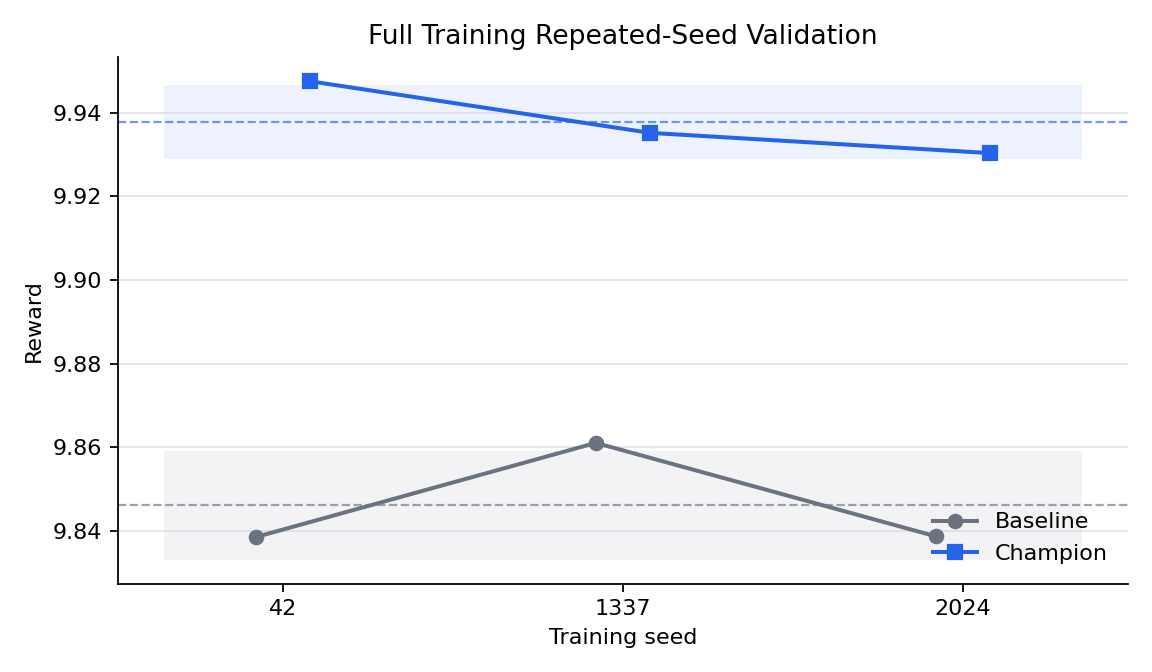
Then the validation was repeated across three training seeds: 42, 1337, and 2024.
The repeated-seed summary:
| Metric | Champion mean | Baseline mean | Difference |
|---|---|---|---|
| Reward | 9.937719 |
9.846051 |
+0.091668 |
| Style score | 0.735496 |
0.749936 |
-0.014440 |
| Preference score | 21.417229 |
21.175372 |
+0.241856 |
| Memorization penalty | 0.082402 |
0.011887 |
+0.070515 |
| Diversity score | 0.295115 |
0.285168 |
+0.009947 |
This is the strongest evidence in the repo. The champion wins on every tested seed, and the mean reward margin is larger than either recipe's seed-to-seed standard deviation in this three-seed sample.
But there is a warning sign: the full-training champion reward (9.937719 mean) is below the original short-run baseline reward (9.965098). That means the short-run scalar score did not transfer as an absolute quality estimate across regimes. It transferred only as a relative comparison between recipes tested under the same longer regime.
6. What changed qualitatively
The component metrics explain the tradeoff. The champion became better under the reward mostly by improving the PickScore preference component and diversity. It did not become more Van Gogh-like by the CLIP style metric; style score decreased. It also moved closer to training images under the DreamSim memorization penalty.
That is not automatically bad. A stronger prompt-following model may produce clearer objects and compositions, and a small increase in memorization penalty may be acceptable if images are still visibly distinct. But it changes how we should describe the result.
The result is not:
The agent discovered a strictly better Van Gogh style model.
The result is:
Under this fixed automatic reward, the agent found a LoRA recipe that consistently scored higher after full retraining, mainly by improving prompt/preference alignment enough to outweigh lower style similarity and higher memorization penalty.


7. Interpretation
The experiment gives a cautious yes.
Yes, an autonomous agent can find useful local improvements for diffusion LoRA training when the problem is tightly constrained. The repo design mattered:
- only one editable file,
- fixed prompts and seeds,
- fixed dataset split,
- fixed promotion rule,
- short trials followed by longer validation,
- and a champion-vs-challenger arena rather than raw scalar sorting.
But the experiment also shows why diffusion AutoResearch is harder than language-model AutoResearch. The reward is a designed proxy, not the task itself. It mixes a preference model, style embeddings, diversity, and a memorization penalty. Each component has its own failure modes, and changing the training regime changes the absolute scale of the reward.
In language-model training, validation loss is usually close enough to the goal that "lower is better" can drive the loop. In diffusion style training, "higher reward" needs decomposition. You need to ask which component moved, whether the result still looks like the target style, whether the model memorized, and whether the win survives new seeds or a longer budget.
8. Limitations
This is a small experiment, not a general benchmark.
First, the validation uses only three training seeds. The margin is larger than observed seed noise in this sample, but more seeds would give a better estimate.
Second, the reward uses automatic metrics. PickScore is useful for preference prediction, CLIP is useful for broad semantic/style similarity, and DreamSim is useful for perceptual similarity, but none is a substitute for human judgment in style-transfer quality.
Third, the task is one artist-style LoRA on one data subset. Van Gogh is intentionally recognizable. The same setup may behave differently for subtler styles, characters, product identity, or multi-concept personalization.
Finally, the full-training reward dropped below the short-run baseline. That means the 10-minute search loop is useful for finding relative candidates, but it should not be read as a calibrated prediction of 2000-step model quality.
9. Takeaways
The practical takeaway is that AutoResearch-style loops are promising for diffusion training, but only if the evaluation harness is treated as an experimental instrument rather than ground truth.
For future runs, I would keep the same constrained design but strengthen validation:
- save full recipe manifests for every accepted champion,
- run repeated-seed validation automatically after a short-run champion is found,
- add a small blind human preference check for final candidates,
- report component metrics alongside reward everywhere,
- and separate "short-run search score" from "full-training validation score" in the UI and logs.
The interesting result is not that an agent beat a baseline once. It is that the agent found a recipe whose relative advantage survived a longer training regime and repeated seeds, while the metric decomposition exposed exactly what that advantage cost.
That is a useful shape of autonomy: not an agent that declares victory from one number, but an agent that can search cheaply, preserve evidence, and hand a scientist a candidate worth validating.
Source notes
Experiment history bundle:
- SHA256:
b313c1d73df68fb836fc19d811ca0ccb90bfec4e4a7cdf748f944cbb2a77ff77 - Branch:
autoresearch/mar20at5b0d533 - Baseline commit:
1260e61 - Short-run champion commit:
5e10fab
External references:
- Experiment repository: https://github.com/azolotenkov/diffusion-autoresearch
- Karpathy AutoResearch: https://github.com/karpathy/autoresearch
- SDXL base model card: https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
- SDXL paper: https://arxiv.org/abs/2307.01952
- LoRA paper: https://arxiv.org/abs/2106.09685
- CLIP paper: https://arxiv.org/abs/2103.00020
- PickScore model card: https://huggingface.co/yuvalkirstain/PickScore_v1
- Pick-a-Pic / PickScore paper: https://arxiv.org/abs/2305.01569
- DreamSim paper: https://arxiv.org/abs/2306.09344
- HugGAN WikiArt dataset: https://huggingface.co/datasets/huggan/wikiart